DualCodec: A Low-Frame-Rate, Semantically-Enhanced Neural Audio Codec for Speech Generation
Abstract
Neural audio codecs serve as the fundamental building blocks for speech language model-based speech generation. To improve speech generation performance, recent neural audio codec SpeechTokenizer proposed to distill the first-layer codec tokens from semantic-rich self-supervised (SSL) representations. Our work improves on this idea of semantically-enhanced audio codec, making it more usable for speech generation. 1) We increase the semantic information accuracy in first-layer codec tokens by proposing a dual encoding method. Dual encoding replaces semantic distillation with a two-stream encoding of SSL and waveform in an end-to-end codec framework. 2) We achieve outstanding low bitrate audio reconstruction quality with DAC-based waveform encoding and adopting larger codebooks. 3) We adopt low frame rates of 25Hz and 12.5Hz to improve speech generation efficiency. The resulting codec model, DualCodec, outperforms existing audio codecs including SpeechTokenizer and Mimi in both audio reconstruction and text-to-speech performance, making it ideal for efficient speech synthesis. We open-source our models and codes.
Architecture of DualCodec
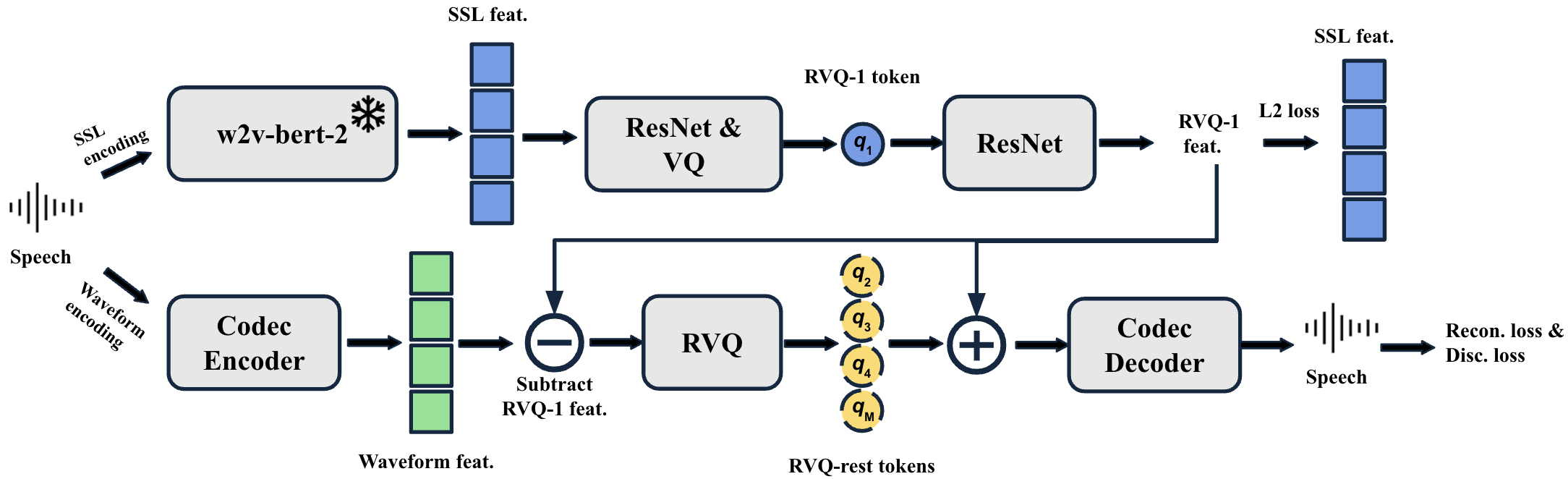
There are two encoding streams in DualCodec: an SSL encoding stream and a waveform encoding stream. The SSL encoding stream captures semantic-rich information to the first-layer codec tokens by directly encoding from SSL feature. The waveform encoding stream encodes and decodes high-quality audio with the proven DAC framework. We apply downsampling to both streams to achieve a low frame rate of 12.5hz or 25hz.
For speech generation model training, both encoding streams are required to obtain training tokens. During SLM inference, only the codec decoder is used to produce audio.
A high-level comparison between codec systems is as follows.
| System | Semantic Enhancement | Audio Quality | Frame Rate |
|---|---|---|---|
| Encodec | ❌ | Good | 75Hz |
| SpeechTokenizer | ✔ (distill) | Good | 50Hz |
| DAC | ❌ | Great | 75Hz/50Hz |
| Mimi | ✔ (distill) | Good | 12.5Hz |
| DualCodec (our work) | ✔ (dual encoding) | Great | 12.5Hz/25Hz |
Low-Bitrate Audio Reconstruction Quality
Neural audio codecs struggle to get high quality audio at low bitrates. In this section, we demonstrate DualCodec's superior audio reconstruction quality compared to other audio codecs.
We select some challenging cases as well as multilingual cases. Note that we only use a small number of quantization levels to compare at low bitrates; in practice, more quantization levels can be used in TTS systems to achieve better audio quality.
| Ground-Truth | DualCodec 12.5Hz (0.93kbps) | DualCodec 25Hz (0.85kbps) | Mimi 12.5Hz (0.83kbps) | WavTokenizer-large 75Hz (0.9kbps) | DAC-official 75Hz (0.75kbps) | Encodec 75Hz (1.5kbps) | SpeechTokenizer 50Hz (1.0kbps) | DAC-reproduced 12.5Hz (0.75kbps) | DAC-reproduced 25Hz (0.75kbps) |
|---|---|---|---|---|---|---|---|---|---|
| Lang: EN | |||||||||
| Lang: EN | |||||||||
| Lang: EN | |||||||||
| Lang: EN | |||||||||
| Lang: JA | |||||||||
| Lang: JA | |||||||||
| Lang: ZH | |||||||||
| Lang: ZH |
Decoding DualCodec's RVQ-1 token (Discretized SSL token)
DualCodec's RVQ-1 tokens are directly extracted from self-supervised (SSL) features. In this section, we demonstrate that DualCodec's RVQ-1 tokens (akin to semantic tokens) has higher intelligibility than semantic-distillation based codec SpeechTokenizer, as well as vanilla audio codec like DAC. Increasing the codebook size can help capture more semantic information.
| Ground-Truth | DualCodec 12.5Hz 1VQ Codebook Size=16384 |
DualCodec 25Hz 1VQ Codebook Size=16384 |
SpeechTokenizer 50Hz 1VQ Codebook Size=1024 |
DAC-reproduced 12.5Hz 1VQ Codebook Size=1024 |
DAC-reproduced 25Hz 1VQ Codebook Size=1024 |
DAC-reproduced 25Hz 1VQ Codebook Size=16384 |
|---|---|---|---|---|---|---|
| Lang: EN | ||||||
| Lang: EN | ||||||
| Lang: EN | ||||||
| Lang: EN | ||||||
| Lang: JA | ||||||
| Lang: JA | ||||||
| Lang: ZH | ||||||
| Lang: ZH |
Text-to-Speech Performance
| Text | Reference Audio | Ground Truth | DualCodec-VALLE 12.5Hz | DualCodec-VALLE 25Hz | Mimi-VALLE | SpeechTokenizer-VALLE | DualCodec-AR+SoundStorm 25Hz | SpeechTokenizer-AR+SoundStorm | Mimi-AR+SoundStorm |
|---|---|---|---|---|---|---|---|---|---|
| Take these capsules over to Mrs. David's house. | |||||||||
| He has the ability to change his head by up to eight different types. | |||||||||
| They can also hike to the panorama restaurant at the top of the mountain. | |||||||||
| My dog is an alsatian, we call her 'Poppy'. | |||||||||
| 眨眼工夫,几个混混亮明警察身份,一瞬间将其将张某制服。 | |||||||||
| 该系列首秀于品牌在伦敦举办的,二零一七二月时装秀上。 | |||||||||
| 可怕的力量,如惊涛骇浪一般汹涌澎湃而出。 | |||||||||
| 什么打仗啦当海盗呀他全无了兴趣。 |
Citation
@inproceedings{dualcodec,
title = {DualCodec: A Low-Frame-Rate, Semantically-Enhanced Neural Audio Codec for Speech Generation},
author = {Li, Jiaqi and Lin, Xiaolong and Li, Zhekai and Huang, Shixi and Wang, Yuancheng and
Wang, Chaoren and Zhan, Zhenpeng and Wu, Zhizheng},
booktitle = {Proceedings of Interspeech 2025},
year = {2025}
}